






大模型时代,物业行业不能缺位
现在大模型非常红火,我参加了好几次学术界的讨论,发现学者不谈大模型,恐怕要落后时代。正好我们课题组从年初的时候,我们就使用ChatGPT进行相关的学术研究和物业行业研究。
同样,物业管理行业也不能缺位AI浪潮,也要找到我们行业可能的切入点。此文正好结合过去大半年时间,我们课题组的一些研究以及所思所想,和大家做一个交流。
现在的物业公司,都完整掌握了依据业主画像设计服务的研究逻辑。例如,我曾经见过碧桂园服务基于社交活动、自我实现意识、身体健康三个指标,建立社区老年人的画像,并最终设计社区养老产品。
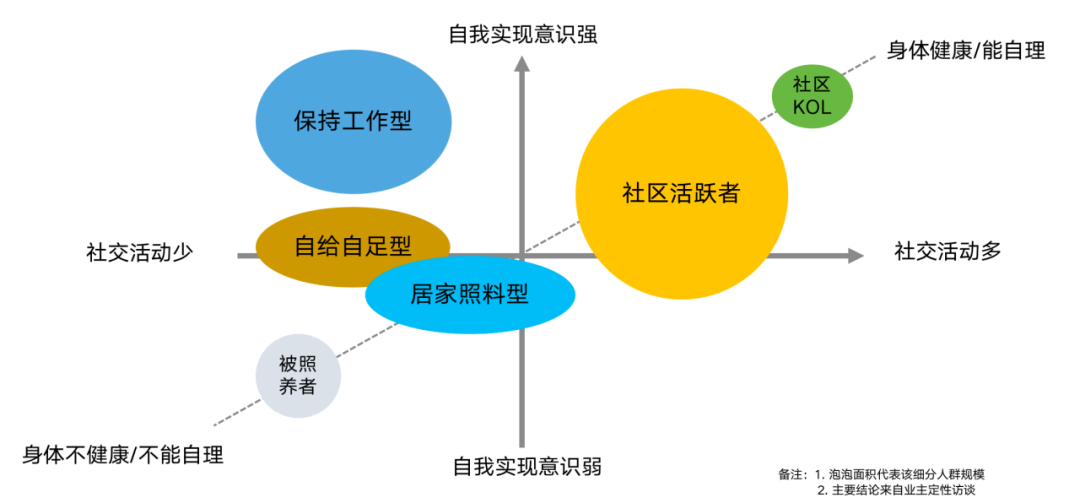
当然,碧桂园服务采取了业主定性访谈的方式,这种方式比较费时费力,对访谈人的能力要求也较高,更重要的是,很多访谈对方根本找不到,无法实现定性访谈。有无更好的方法,能够高效率提升用户画像效率。
显然,诸如ChatGPT通用大模型,获取业主画像的效率更明显。
正好,今年年初,我们帮助一家物业公司设计国家实验室物业服务体系,其中一部分就涉及科学家物业服务。显然,大面积访谈科学家群体是不现实的,我们采用ChatGPT通用大模型,快速生成科学家群体用户画像。

无论是社区的老年人,还是实验室的科学家,其群体特征并不是专属于物业行业,借助通用大模型是非常有效的研究手段。
但是,通用大模型数据大多来自于公开文献与网络信息,专业行业数据积累不足,必须让模型由通才转化为行业专才,才能提高纵深领域任务处理能力。例如,近几年国家一直积极推进基层治理相关的美好家园建设、党建引领物业管理、“四好建设”的选树活动。选树的目的不是简单局限在街道、业主和企业最佳实践的展示,根本目的是通过大量的选树活动,找到中国基层社区治理的路径和模式,以及路径舒畅形成的关键因素和变量。这个时候,建立物业行业大模型,采取文本分析的方法,就可以在保持基础大模型精度的同时,大幅降低资源开销与训练成本。
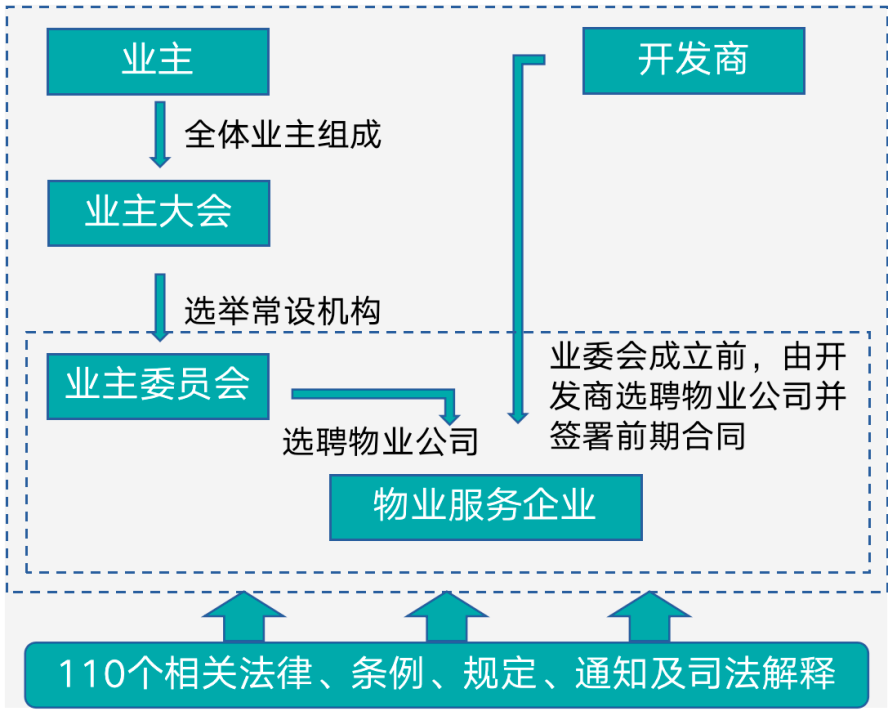
同样的道理,中国与物业管理有关的法律非常复杂,初步统计一下,国家层面超过110部相关法律、条例、规定、通知及司法解释,用来规范物业服务企业、业主及业委会的行为。以《住宅室内装饰装修管理方法》为例,第三章开工申报与监督中提到报告有关部门依法处理。问题就产生了,什么是有关部门,不同城市约定也不一样,国家层面法律也不可能规定这么详细。如何解决?通过GPT-4打造物业行业法律的生成式AI服务,专注法律文本分析。大模型在法律的落地场景非常明确,从文书整理 ,案情分析,案例收集比对证据收集和校对都有直接应用价值。
构建法律大模型,已经有先例。今年6月26日,汤森路透以6.5亿美元现金收购了法律技术服务商Casetext。Casetext的核心产品之一 CoCounsel,是通过GPT-4打造的一款专注法律领域的ChatGPT产品,可实现分析法律文件、合同、生成证词和法律备忘录等。未来Casetext的产品矩阵将与汤森路透的核心法律产品Westlaw进行技术融合,为汤森路透的客户群提供法律领域的生成式AI服务。
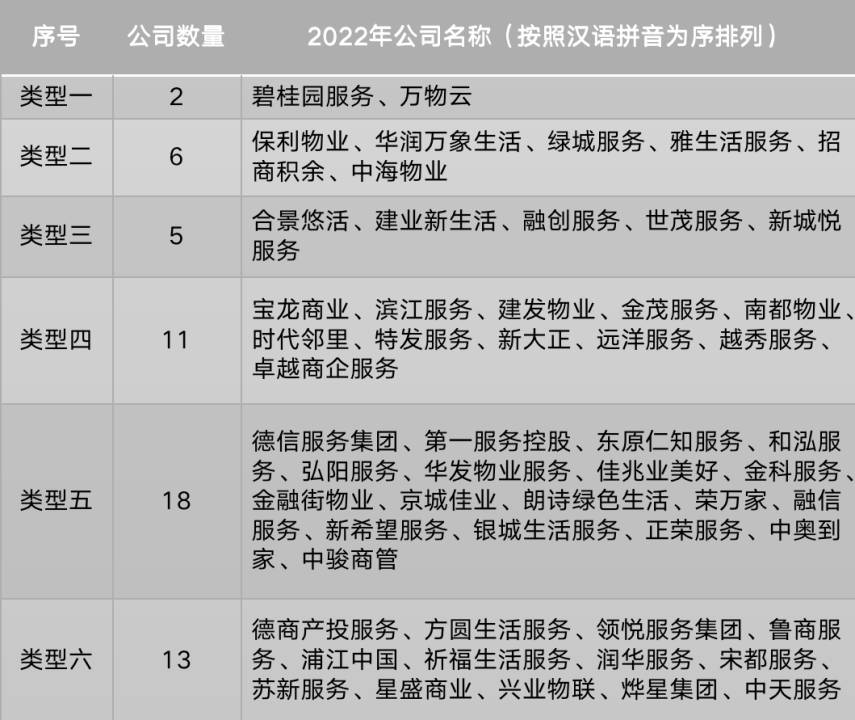
此外,每年我们课题组为了训练学生,都要进行上市物业公司的财务表格分析,诸如简单财务报表分析,技术要求不高,有些风险评估分析,技术要求就较高。目前,我们就遇到一个迫切提高研究效率的问题。我们课题组可以根据三四个指标,采用最优分割法,把上市物业公司分成6种类型。其实,我们特别想进一步横向比较相同类型的上市物业公司,包括投资策略建议、风险评估、股票预测、金融新闻摘要、公司财报分析、债券评级和市场趋势分析等业务场景。这些研究都极其消耗时间和人力资源,如果出现针对物业行业的金融大模型一定会好很多。
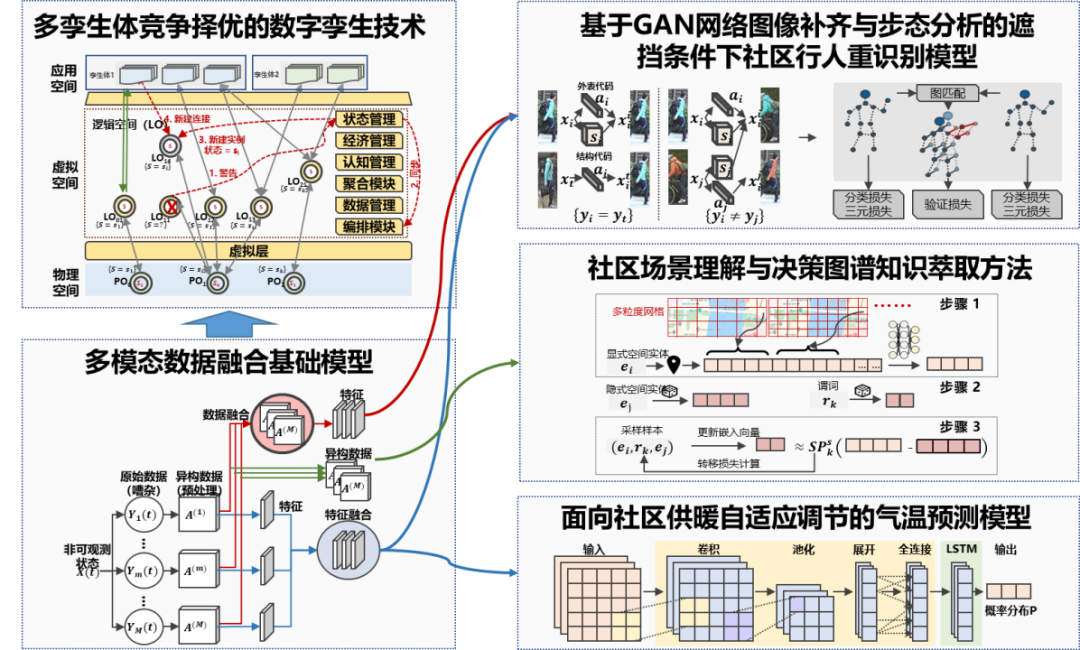
众所周知,大模型的训练依赖于先进的算法。这些算法包括深度学习、强化学习、迁移学习等,它们可以帮助模型在大量数据中快速找到有效的特征和规律。我们完全可以设想,基于多模态数据融合基础模型,既可以找到面向社区供暖自适应调节的气温预测模型,用来降低社区碳排放,也可以社区场景理解模式以及行人识别模型。例如,我们课题组今年参与设计寄宿制高中的物业安全管理体系,其中我们就提出,可否利用摄像头,及早识别和发现有抑郁症倾向的高中生,这也是学校物业安全管理预防重于应急理念的落地。这个想法最终能够完全落地,极大可能需要大模型获取抑郁症群体特征。
新一轮的AI已来,中国的物业管理行业不仅不能缺位,而且一定会大放异彩,甚至可能是改变物业行业困境的一把利刃。
此文是我在2023广州物业博览会物业进化论论坛的发言节选。
